

Crawl budget, czyli budżet indeksowania, to ilość adresów URL, które może odwiedzić robot Google podczas jednej sesji indeksowania. W tym artykule dowiesz się, jak jest obliczany, jak zoptymalizować jego wykorzystanie oraz poznasz popularne błędy powodujące marnowanie budżetu indeksowania.
Dlaczego Google określa crawl budget?
Budżet indeksowania jest z góry określony ze względu na ograniczone zasoby komputerowe. Wyszukiwarka musi nadawać priorytety przy indeksowaniu ponieważ nie jest w stanie zauważyć codziennych zmian na wszystkich stronach internetowych. To naszym zadaniem jest ułatwienie robotom wyszukiwarek indeksacji naszej strony oraz wskazanie im priorytetowych sekcji do indeksowania.

W jaki sposób algorytm wyszukiwarki oblicza Crawl Budget?
Oficjalne informacje mówią o 2 elementach, które mają wpływ na wielkość budżetu indeksowania.
Limit wydajności indeksowania
Każdy serwer jest inny, jeden jest ultraszybki, a drugi — mniej wydajny. Na podstawie czasu odpowiedzi serwera (TTFB), na którym jest nasza strona internetowa i czasu ładowania strony Google ustala ilość jednoczesnych połączeń, jakie może wykonać, a także określa odstęp pomiędzy każdym z zapytań.
Im szybszy serwer tym robot wyszukiwarki może pozwolić sobie na wydajniejsze indeksowanie strony internetowej. Analogicznie dla wolniejszych stron – Google zmniejsza ilość odwiedzin, by zbytnio nie obciążać serwera WWW.
Zapotrzebowanie na indeksowanie
Sieć Internet zawiera ogromną ilość stron internetowych, jedne są popularne i codziennie aktualizowane, a inne – mniej popularne, a ich treść jest praktycznie statyczna. Przykładowo, strona z godzinową prognozą pogody musi być odświeżana nawet kilka razy dziennie, a przepis na ciasto marchewkowe raz na miesiąc. Newsy ze znanego portalu informacyjnego muszą wpadać do indeksu praktycznie od razu, a wpisy z bloga o amatorskiej stolarce już nie.
Opierając się na zebranych danych Google ustala priorytety:
- którą domenę indeksować częściej, a którą rzadziej,
- które podstrony indeksować często, a które rzadko,
- ile podstron zaindeksować w jednej sesji.
Jak sprawdzić jaki jest mój crawl budget?
Dokładna ilość przydzielonych nam „kredytów” nie jest publicznie podana, ale korzystając z danych z Google Search Console, jesteśmy w stanie sprawdzić, czy crawl budget jest w porządku lub, czy możemy mieć kłopoty z indeksacją. Zalogujmy się do GSC i przejdźmy do sekcji „Ustawienia” -> „Statystyki indeksowania”. Pokaże się nam wykres z ilością zapytań Googlebota w czasie:
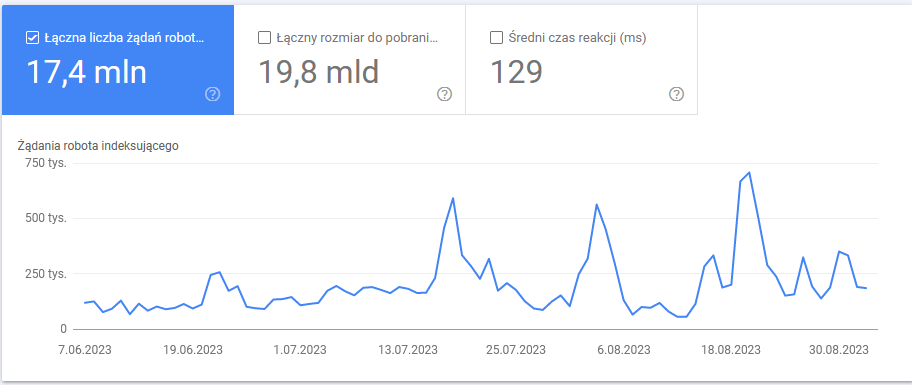
Powyższy wykres dotyczy portalu z około 600 000 podstron. Dane oscylują między 50 000, a 150 000 żądań dziennie i dochodzą do 700 000 podczas aktualizacji algorytmu. Należy pamiętać, że wśród tych liczb są również pliki związane z szablonem strony (logo, skrypty czy style), a także fotografie dołączone do artykułów.
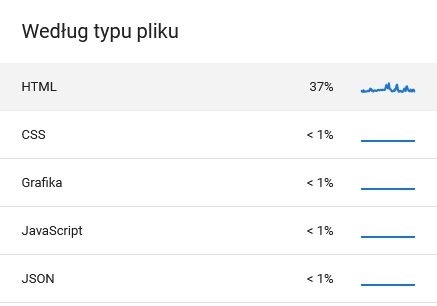
Informacje o tym znajdziemy w boksach pod wykresem. GSC informuje nas jakiego rodzaju dokumenty pobiera:
a także ile zasobów przeznacza na wykrycie nowych dokumentów, a ile na odświeżenie uprzednio odwiedzonych:

Jak zoptymalizować i w pełni wykorzystać przydzielony crawl budget?
Dobre praktyki w optymalizacji crawl budgetu
Blokada podstron w robots.txt
Ten plik Googlebot odczytuje na początku sesji indeksowania, by nie marnować czasu na zablokowane podstrony. Warto w nim umieścić zbędne podstrony, jak wyniki wyszukiwania czy część funkcji z nawigacji fasetowej.
Użycie linków kanonicznych
Link kanoniczny informuje robota wyszukiwarki o oryginalnym adresie danego dokumentu. Chroni nasze podstrony przed możliwym wykryciem duplikatów. Warto zastosować je na całej stronie, a szczególnie w listingach kategorii, które oferują opcje np. sortowania. Innym przypadkiem jest posiadanie w sklepie produktów, które różnią się tylko kolorem i nie mamy możliwości ich złączyć w jedną kartę produktową.
Kontrola duplikatów
Warto sprawdzić, czy w obrębie i poza naszą stroną nie są wyświetlane te same treści więcej niż jeden raz. W przypadku ich wykrycia należy się ich pozbyć przez usunięcie/przekierowanie na oryginał lub wykorzystać link kanoniczny.
Optymalizacja linkowania wewnętrznego
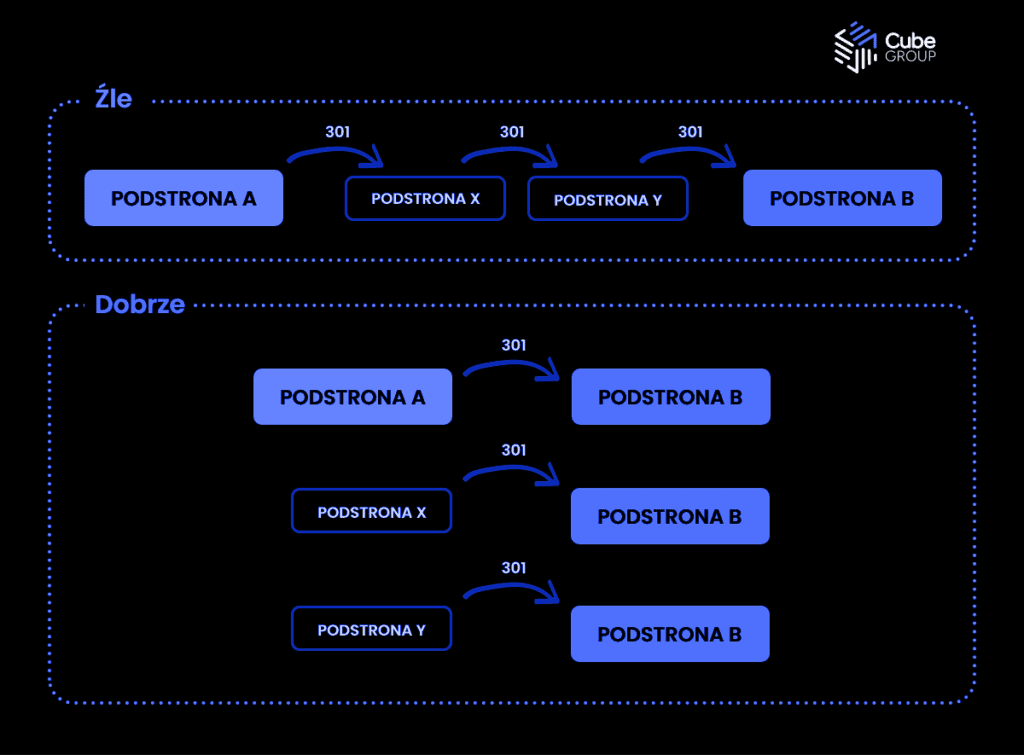
Zapewnij większą ilość linków do ważnych podstron. Dzięki temu będą łatwiej i częściej odwiedzane przez Googlebota. Upewnij się, że nasza strona jest dostępna tylko pod jednym protokołem HTTPS i czy np. wersja z „www” przekierowuje na wersję „bez www” w adresie. Usuwając czy zmieniając adres produktu sprawdź, czy nie prowadzą do niego linki z bloga, czy z zewnętrznych stron internetowych. Upewnij się również, że przekierowania są bezpośrednie (zamiast A->B->C użyj A->C i B->C).
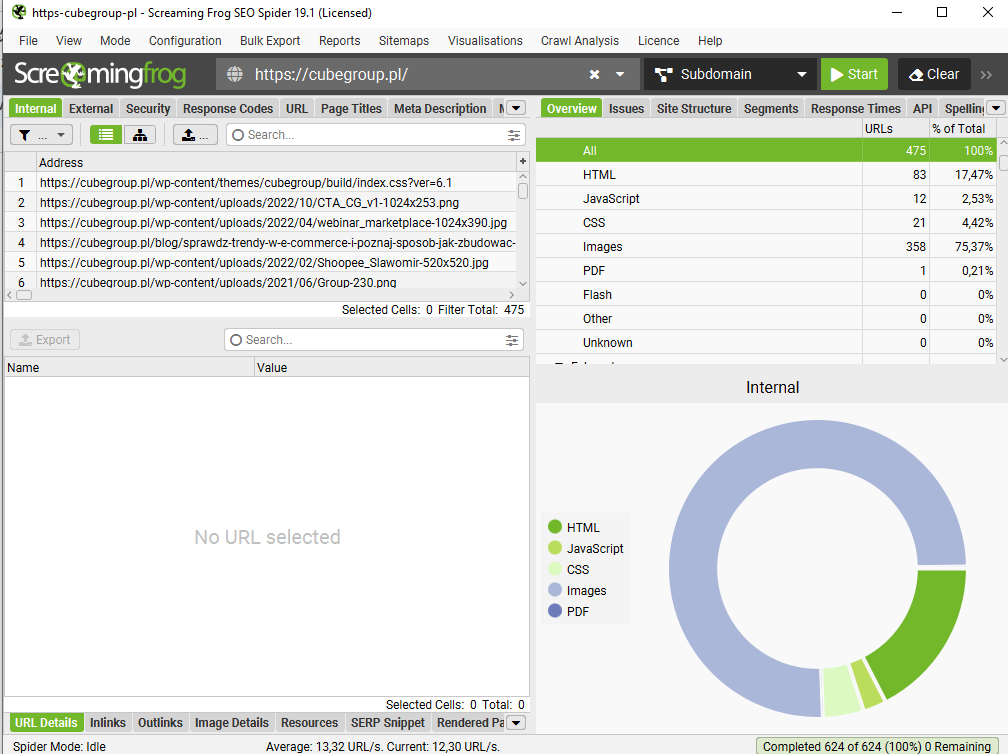
Świetnym narzędziem do analizy linkowania wewnętrznego jest płatny Screaming Frog
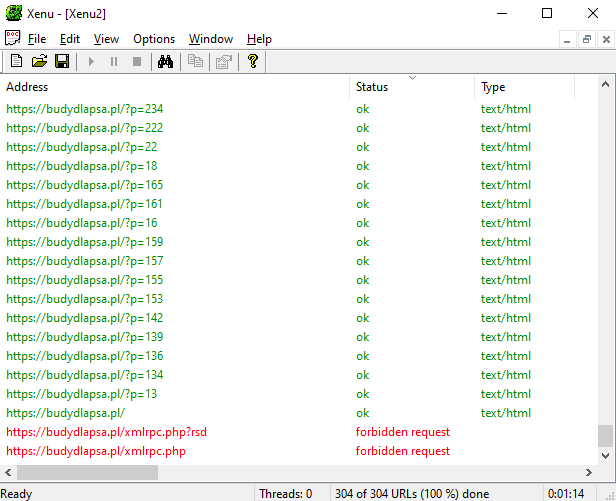
Programem bardziej ubogim w funkcje, ale do optymalizacji crawl budgetu wystarczającym i w pełni darmowym jest Xenu’s Link Sleuth:
Optymalizacja prędkości serwera/CMSa
Warto sprawdzić, czy nasz serwer jest wystarczający dla liczby internautów, którzy odwiedzają naszą stronę internetową — czy w godzinach szczytu strona wczytuje się równie szybko jak poza nimi? Oprócz tego warto sprawdzić, czy w CMSie jest dostępna opcja cache’owania zapytań do bazy danych — często rozwiązujemy tym problem z prędkością.
Analiza logów serwera
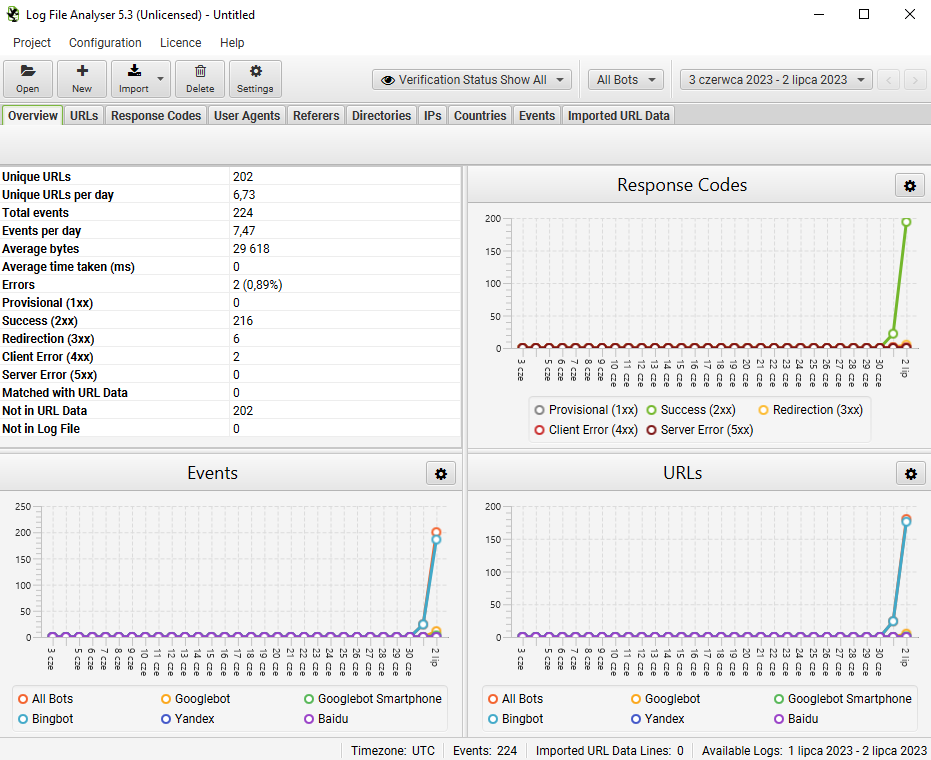
Przeanalizuj logi serwera. Dzięki temu dokładnie sprawdzisz jak i gdzie poruszają się roboty wyszukiwarek. Szczególną uwagę zwróć na nagłówki HTTP inne niż 200 OK. Ciekawym narzędziem ułatwiającym analizę jest „SEO Log File Analyser” od producenta znanego z programu Screaming Frog.
Utworzenie mapy podstron
Mapę XML tworzy się w celu wskazania robotom wyszukiwarek naszych priorytetowych podstron. Przykładowa mapa wygląda tak:
| <?xml version=”1.0″ encoding=”UTF-8″?> <urlset xmlns=”http://www.sitemaps.org/schemas/sitemap/0.9″> <url> <loc>http://www.example.com/</loc> <lastmod>2005-01-01</lastmod> <changefreq>monthly</changefreq> <priority>0.8</priority> </url> </urlset> |
Tak stworzony plik należy dodać w Google Search Console w sekcji „Indeksowanie -> Mapy witryn”.
Weryfikacja problemów w Google Search Console
Google nie pozostawia nam pola do domysłów i udostępnia nam informacje diagnostyczne w byłych narzędziach dla webmasterów — Google Search Console (GSC). Są to zarówno problemy, jakie robot napotkał, ale także komunikaty o naturalnych przypadkach. Dzięki tym informacjom możemy obserwować zachowanie indeksu podczas optymalizacji czy migracji strony internetowej.
Aby poznać te informacje, zaloguj się do GSC, przejdź po lewej stronie do sekcji “Indeksowanie” i wybierz pozycję “Strony”. Otworzy się podsumowanie z ilością zaindeksowanych i niezaindeksowanych podstron.
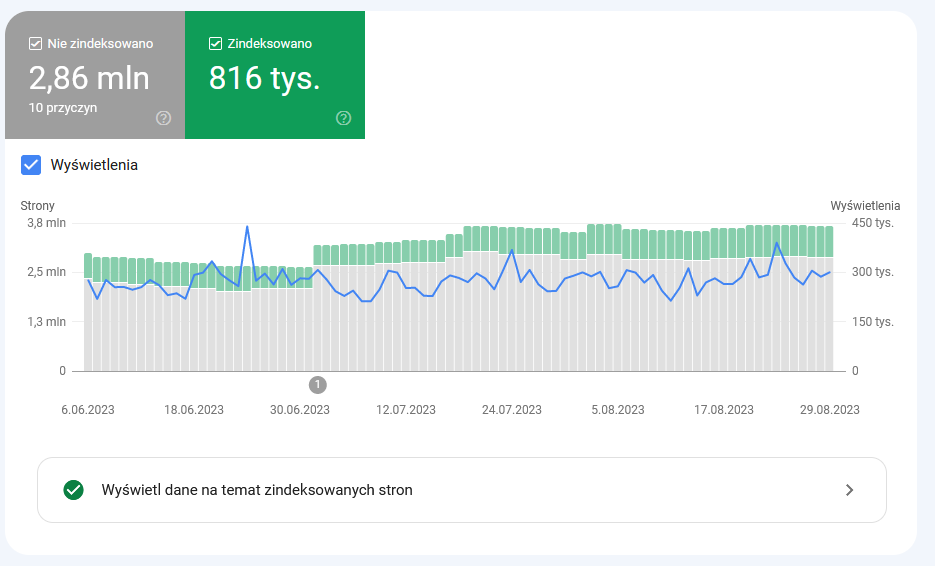
Z powyższego wykresu możemy odczytać kilka ważnych informacji:
- ile podstron jest w indeksie,
- kiedy nastąpił skok/spadek ilości zaindeksowanych podstron,
- ile podstron nie jest w indeksie,
- kiedy nastąpił skok/spadek ilości niezaindeksowanych podstron,
- czy jakikolwiek z powyższych skoków ma wpływ na ilość wyświetleń naszej strony w wyszukiwarce.
Pod wykresem znajdziesz listę przyczyn niezaindeksowania podstron podzieloną na grupy.
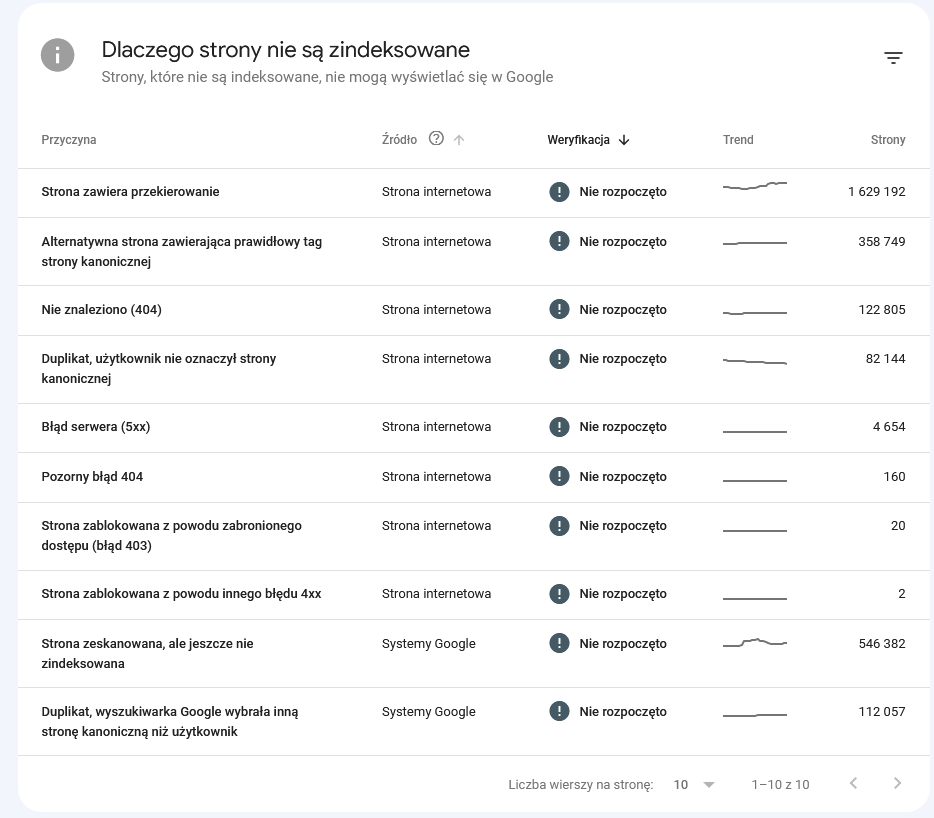
Naprawa wykrytych problemów w Google Search Console
Czy każda przyczyna podana przez Google jest realnym problemem i wymaga naprawy? Poniżej wyjaśniam wpływ danej przyczyny na indeksację i możliwe rozwiązanie.
Strona zawiera przekierowanie
Załóżmy sytuację, w której autor bloga odświeżył ranking produktów zamieniając TOPowe produkty z 2022 na najlepiej sprzedające się w 2023. W związku z tym autor zmienił też adres URL wpisu z domena.pl/ranking-produktow-2022 na domena.pl/ranking-produktow-2023, a system CMS wykonał automatycznie przekierowanie 301 ze starego adresu na nowy.
Dokładnie to jest raportowane w GSC jako strona zawierająca przekierowanie. Nie ma tutaj żadnego błędu i jest to sytuacja całkowicie normalna i codzienna. To na co warto zwrócić uwagę to poprawienie linkowania wewnętrznego tak, aby linki z innych wpisów na blogu prowadziły do nowego adresu z 2023 w URLu. Właśnie zaoszczędziliśmy trochę crawl budgetu.
| Częstym też błędem jest linkowanie wewnętrzne www/bez www lub z http do https. |
Alternatywna strona zawierająca prawidłowy tag strony kanonicznej
Link kanoniczny wskazuje robotom Google, pod jakim adresem znajduje się oryginalna wersja danej treści. Jest to przydatne, aby robot nie indeksował np. listingu produktów z włączonym sortowaniem (zbiór produktów jest taki sam, zmieniła się tylko kolejność).
Ten komunikat informuje nas, że robot Google znalazł dla danej podstrony duplikat, ale zawiera on link kanoniczny wskazujący oryginał. Wszystko jest porządku, ale warto przejrzeć skąd te duplikaty — być może jest coś do naprawienia w linkowaniu wewnętrznym i zaoszczędzimy w ten sposób craw budget.
Nie znaleziono (404)
Załóżmy sytuację, w której nie masz i nie będziesz już miał określonego produktu, a na sklepie nie istnieje produkt podobny i nie wykonujesz przekierowania. W tym przypadku podstrona produktu powinna wyświetlić błąd 404. Jest to sytuacja całkowicie normalna.
Na co warto zwrócić uwagę?
Należy pamiętać o czytelnikach bloga sklepowego — może w którymś z poradników był podlinkowany skasowany produkt? Czy do produktu prowadzą linki z innych stron internetowych? By nie gubić czytelników i jednocześnie oszczędzać crawl budget należy monitorować zarówno linki wewnętrzne jak i zewnętrzne, by zawsze kierowały do poprawnej podstrony. Warto przejrzeć ręcznie podstrony z listy „Nie znaleziono (404)” i jeśli zobaczymy wartościowe linki z zewnątrz to przywrócić dokument lub przekierować go w pasujące miejsce.
Duplikat, użytkownik nie oznaczył strony kanonicznej
Przyczyna bardzo prosta – ta sama podstrona istnieje pod więcej niż jednym adresem i nie ma linka kanonicznego, który by wskazywał oryginał.
Warto więc wdrożyć linki kanoniczne na całej stronie. Sprawdź jak wdrożyć linki kanoniczne.
Błąd serwera (5xx)
Ten komunikat informuje, że wystąpiły problemy z samym serwerem. Najpopularniejsze błędy 5xx to:
- error 500 (internal server error) czyli wewnętrzny błąd serwera. Należy skonsultować z administratorem serwera/hostingiem.
- error 503 (service unavailable) czyli serwer działa poprawnie, ale nie może w tym momencie obsłużyć zapytania. Zdarza się na hostingach, że taki błąd jest wyświetlany przy przekroczeniu dostępnych zasobów, np. procesora. Również należy skonsultować z administratorem serwera/hostingiem.
Częste występowanie tego rodzaju błędów spowoduje spowolnienie indeksacji przez roboty wyszukiwarki.
Pozorny błąd 404
Ten komunikat informuje, że dana strona wygląda jak strona błędu „404 nie znaleziono”, ale nie informuje o tym w nagłówku HTTP. O tym, że podstrona nie istnieje musimy poinformować zarówno człowieka-internautę przez stosowny komunikat, ale również roboty — właśnie przez nagłówek HTTP. Brak nagłówka 404/410 powoduje, że robot Google ciągle wraca i sprawdza dany dokument — crawl budget jest marnowany.
Strona zablokowana z powodu zabronionego dostępu (błąd 403)
Błąd 403 „Forbidden” to informacja, że serwer nie może dać dostępu do danego dokumentu. Wynika to z ustawień serwera.
Ten komunikat z Search Consoli informuje nas, że na stronie lub na zewnątrz istnieją linki, które prowadzą do podstron na naszej stronie, które wyświetlają błąd 403. Należy zweryfikować zasadność błędu 403 lub poprawność prowadzących do niego linków.
Strona zablokowana z powodu innego błędu 4xx
Ta przyczyna to najczęściej błąd typu 405 „Niedozwolona metoda” i jest związana z np. komunikacją JavaScriptu z serwerem. Oznacza, że serwer oczekiwał innej metody komunikacji, niż została mu zaserwowana, a z reguły mylone są dwie najpopularniejsze — POST i GET. Problem należy zweryfikować z webmasterem.
Strona zeskanowana, ale jeszcze nie zindeksowana
Do tej przyczyny należy przyłożyć większą uwagę. Oznacza ona, że robot Google trafił na daną podstronę, ale coś mu się nie spodobało i odłożył w czasie jej ponowne sprawdzenie/indeksację. Przyczyną może być, że strona jest nowa i wciąż buduje swoje zaufania, a także niespełnienie wymagań jakościowych takie jak:
- zbyt krótka treść,
- brak merytoryki w treści (niska jakość w porównaniu z podobnymi),
- zduplikowana treść,
- zbyt głębokie/słabe podlinkowanie wewnętrzne.
Duplikat, wyszukiwarka Google wybrała inną stronę kanoniczną niż użytkownik
Ten komunikat to ważny podpunkt dla optymalizacji crawl budgetu. Link kanoniczny działa tylko jeśli dwie podstrony są do siebie podobne. Ta informacja oznacza więc, że wyszukiwarka wybrała samodzielnie, lepszą jej zdaniem, podstronę jako kanoniczną. Najczęściej link kanoniczny został źle przypisany — sprawdź dany URL w Google Search Consoli oraz porównaj URL wybranej podstrony z zawartością link canonical w kodzie strony.
Strona wykluczona za pomocą tagu „noindex”
Ważny dla optymalizacji budżetu indeksowania podpunkt. Podstrony, które mają tag/nagłówek noindex są crawlowane, ale nie indeksowane. Oznacza to, że robot Google może po nich przez żadnych przeszkód “chodzić” i podążać za obecnymi na nich linkami. Zależnie od danego przypadku, można zablokować dane podstrony przed indeksacją za pomocą pliku robots.txt. Tylko blokada w robots.txt oszczędza crawl budget, noindex nam w tym przypadku nie pomaga.
Strona zablokowana przez plik robots.txt
Ten plik to nasz przyjaciel w optymalizacji budżetu indeksowania. Warto w nim wykluczyć podstrony, których robot Google nie powinien widzieć. W e‑commerce dobrym przykładem jest nawigacja fasetowa. Podczas wybierania przez użytkownika parametrów tworzą się nieraz dziesiątki tysięcy adresów URL. Warto w takim wypadku zablokować podstrony bez wolumenu wyszukiwań.
Strona wykryta – obecnie niezindeksowana
W tym przypadku robot Google miał problem podczas skanowania podstrony. Mogło dojść do np. przeciążenie serwera. Robot powinien sam za jakiś czas wrócić. Dla pewności warto przejrzeć jakość podstrony oraz logi serwera — czy nie powoduje ona błędów na serwerze.
Błąd przekierowania
Ten komunikat informuje nas, że robot Google nie mógł wyświetlić strony, na którą jest wykonane przekierowanie. Z Reguły jest to tzw. pętla przekierowań, czyli np.:
| Strona A wykonuje przekierowanie 301 -> na stronę B, a strona B wykonuje przekierowanie 301 -> z powrotem na stronę A. Naprawa polega na zmianie przekierowań na poprawne. |


